Having discussed in my last blog some of the reasons why data ends up where it does, this time we’ll have a look at a new Azure feature from Microsoft that will help users and network administrators to start moving data to the cloud, without the less-attentive user even knowing.
This new feature is called Azure File Sync.
Azure Files
Azure File Sync is a new feature within Azure Files. If you’re unfamiliar with Azure Files, it’s best described as a storage service within Azure that provides users with access to shares over SMB. Or in other words, it enables you to put data in shares hosted in the cloud, but separately to SaaS-provided facilities such as OneDrive or SharePoint Online. It’s a service, so isn’t specifically attached to a server – in much the same way as Blob storage, if you’re familiar with that. If you’re not, you’re probably laughing at the fact that there’s a type of storage called Blob.
Azure Files has been generally available since September 2015, so it’s been around for a while now. Azure File Sync is still in public preview and is still developing, as you’ll see if you read on.
Connecting to an Azure Files Share
The concept behind Azure Files is relatively simple; the user can directly access the Azure Files share – if they have a device that supports SMBv3, know the Azure Storage Account name and the name of the share, and have the primary or secondary storage key – or if their network administrator configures it for them via PowerShell or a command line script. They can even map a network drive to the share, and if you’ve read my previous blog you’ll understand how that might be helpful. All of this assumes port 445 (outbound) is open through the firewall – this is the port that SMB uses. The net result looks very simple:
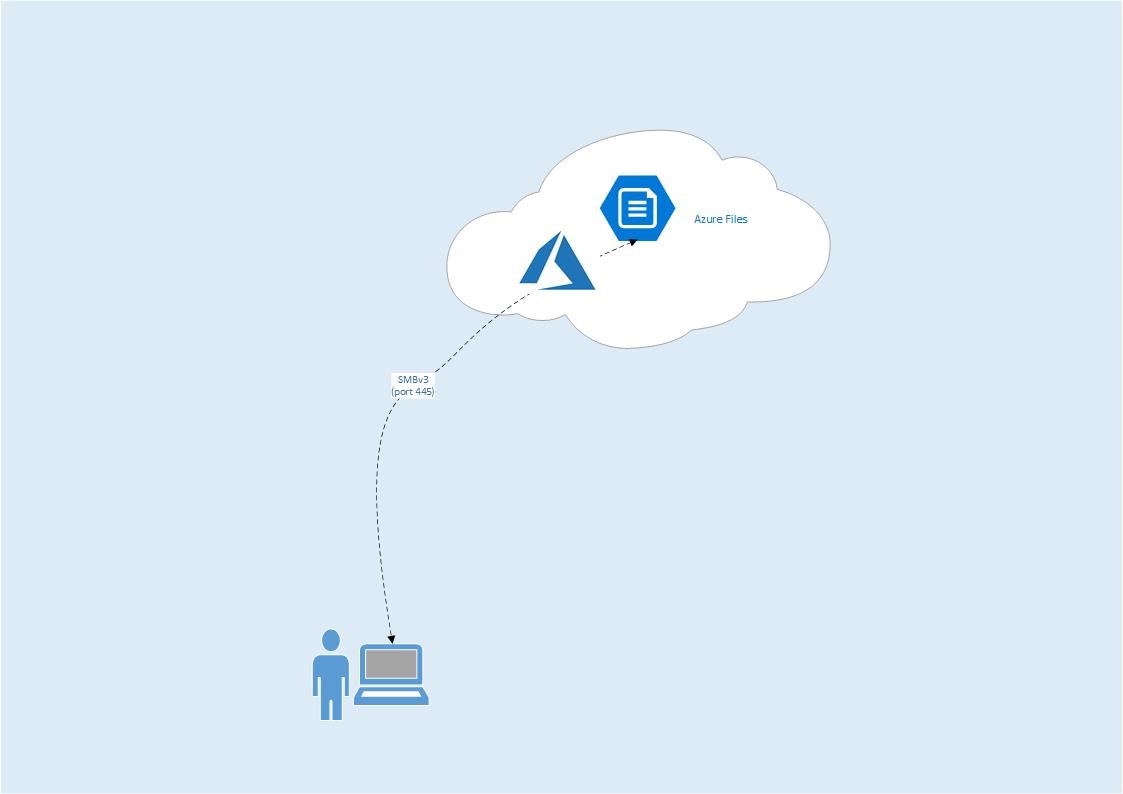
The benefit of such a configuration is that because the share is in Azure, it’s accessible from anywhere. There aren’t the same restrictions that would be there if the share was on a server in the school.
The downside, as it stands, is that there is no granular access control over the share. If you have the details listed above, you can access the data in the share. That makes it less useful as a general-purpose file share, unless you have a group of users who have equal billing and require the same level of access to any data in the share.
Azure File Sync
Compared with Azure Files, Azure File Sync is a different execution that still uses an Azure Files share but has an intermediary stage for the data involved. In this execution, data is stored in a traditional on-premise file share and it is that file share that is synchronised up to the Azure Files share.
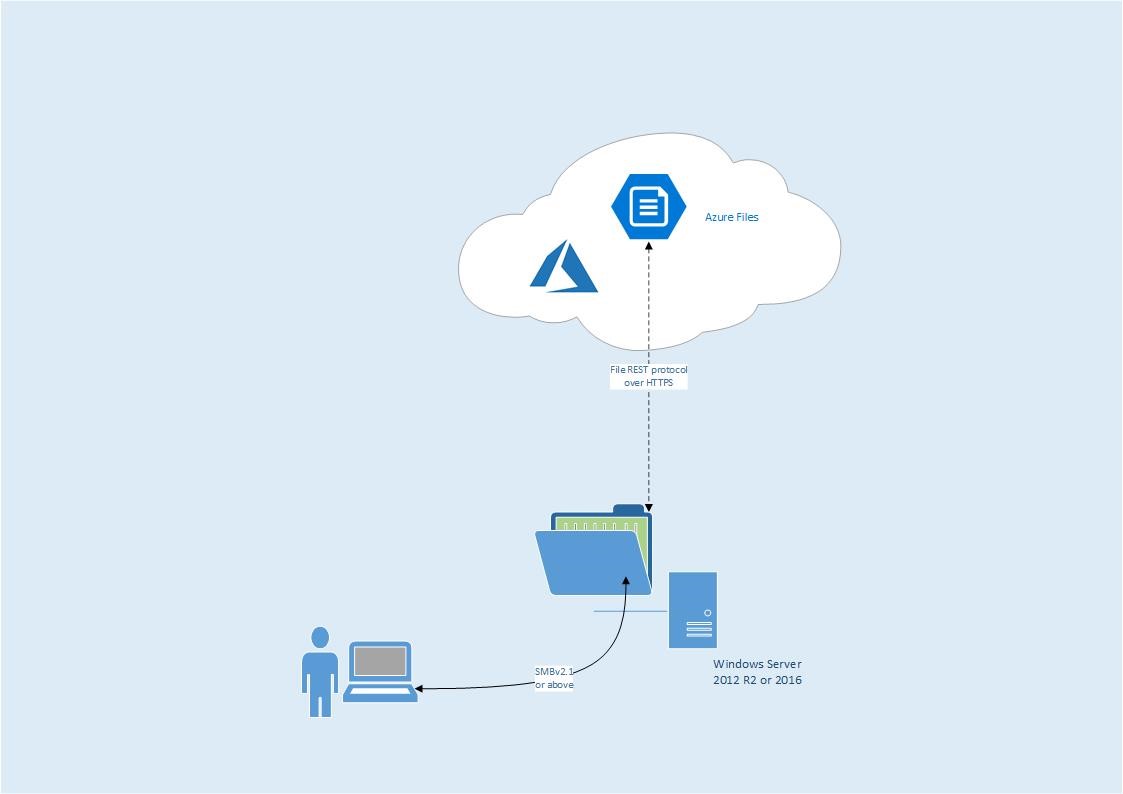
There are several benefits to this approach:
- Granular share and NTFS permissions can be set on the on-premise file share location, which makes the share more broadly available.
- Users can connect to the on-premise share using SMBv2.1 or above, meaning more client types can natively connect.
- It’s straight forward to map a drive to the on-premise share.
- With synchronisation taking place between the file share and Azure Files, the user is oblivious to the fact that their data is also being stored in the cloud.
- From the administrator’s point of view, there’s no need to share details of the Azure Storage Account (such as its name and the storage key) with users.
- Synchronisation takes place using the File REST protocol over HTTPS, so there’s no need to open up port 445 outbound.
But there are also a few imperfections. Because the data is still stored in the cloud in an Azure Files share it could still be accessible remotely, but as it stands any granular permissions set on premise are not honoured in the cloud. Any changes to the data directly in the Azure Files share could take up to 24 hours to synchronise down to the on-premise share. As a result, this may not be an immediate solution for data access from anywhere.
Cloud Tiering
So far, we’ve established a rudimentary view of Azure File Sync, but that alone wouldn’t have attracted enough interest – either in the product itself or for me to blog about. Things get really interesting from this point forwards.
The feature that drew me to look at Azure File Sync in the first place is its support for cloud tiering – when a configurable threshold is reached, no more local storage will be consumed; instead, data beyond the threshold is stored in the Azure Files share but for all intents and purposes still looks to the user as though it is stored on premise. At the moment the concept is quite simple, with most recently accessed data held locally (and in the Azure Files share) and ‘cooler’ data – not recently accessed – only stored in the Azure Files share. The only hint to the user is the file’s icon in File Explorer; on Windows Server 2016 it shows cloud-only files with a greyed icon, and on-premise files with a more solid icon:

The File Explorer view from a Windows 10 device is slightly different, with crosses appearing over icons for files that are stored only in Azure:
Cloud tiering is enabled on the server endpoint – the on-premise server share – through Sync Group configuration in the Azure portal. Once enabled, you have the option to define the amount of free space the volume on which the file share resides can reduce to before tiering initiates. To some, this may be a little counter-intuitive; the greater the percentage set, the earlier tiering will begin. For example, configuring the volume free space setting to be 90% will result in tiering when only 10% of the capacity available to that volume is consumed.
It’s worth noting that the setting is for the volume, so things could get a little complicated if you were to invoke tiering on multiple shares held on the same volume – particularly if you set the tiering settings differently.
We’ll discuss multiple shares and the broader setup in a while, but first I want to emphasise the benefits of cloud tiering; in resource-constrained school networks where storage can be a premium and not easy to extend, being able to manage the local storage as a known quantity and instead use cloud elasticity for ‘overspill’ has to be a boon, particularly when it’s the infrequently or never used data that is tiered and no longer taking up valuable local storage. And as the Azure Files share is always the master copy, containing all of the data for the file share, it’s also supporting the school’s transition to the cloud.
Danger, Will Robinson!
As the robot in Lost in Space warns the young crew member, there are a couple of important things to be aware of when utilising tiering functionality.
Both local backup solutions and anti-virus scanning have the potential to trigger an unintended recall of tiered files. The good news is there are solutions to these challenges.
For backups, use a cloud backup solution to back up the Azure Files share, rather than a local backup solution to back up the server endpoint.
For anti-virus, use software that is able to skip reading of offline files, and ensure that option is configured.
Azure File Sync Construct
So far, we’ve covered the basic functionality of an Azure File Sync deployment. Before we go further I should explain, briefly, the deployment construct, as that should help with how straight forward it is to grow the solution. Microsoft’s current favoured vernacular for a change of direction like this is ‘shifting gears’. Yuck.
The starting point is in the Azure portal, where the Storage Sync Service needs to be deployed. As we’re in preview the service isn’t available in all regions yet; West Europe was included from the start, and UK South has recently been added. North Europe is anticipated before GA is announced.
Next, each server that will host a file share to be synchronised needs to be registered with the Storage Sync Service. This involves installing an agent on the server and giving it information about the Azure subscription and Resource Group holding the service, and the name of the Storage Sync Service itself. Servers can be 2012 R2 or 2016, but will need PowerShell 5.1 or above (which is native to 2016 anyway). One slight quirk is that Cloud Solution Provider (CSP) subscriptions cannot use the agent installer UI at the moment, so must be registered via PowerShell.
After that, a Sync Group can be created. Simply, a Sync Group defines the endpoints that will be kept in sync with each other. Currently, it can contain one cloud endpoint – an Azure Files share – and one or more Server endpoint – a share located on a registered on-premise server, defined by its absolute path on the volume, including drive letter.
That’s it. If all is well, any data on the server endpoint(s) will start synchronising with the cloud endpoint, and by extension, with each other.
And if you want to synchronise more than one file share, you just create another Sync Group for each share.
Multi-site Synchronisation
There was a clue there. All endpoints in a Sync Group will remain in sync with each other as the relationship is between the server endpoint and the cloud endpoint. The master is the cloud endpoint. Therefore, all server endpoints in the same Sync Group will have access to the same data set, no matter where they are physically located.
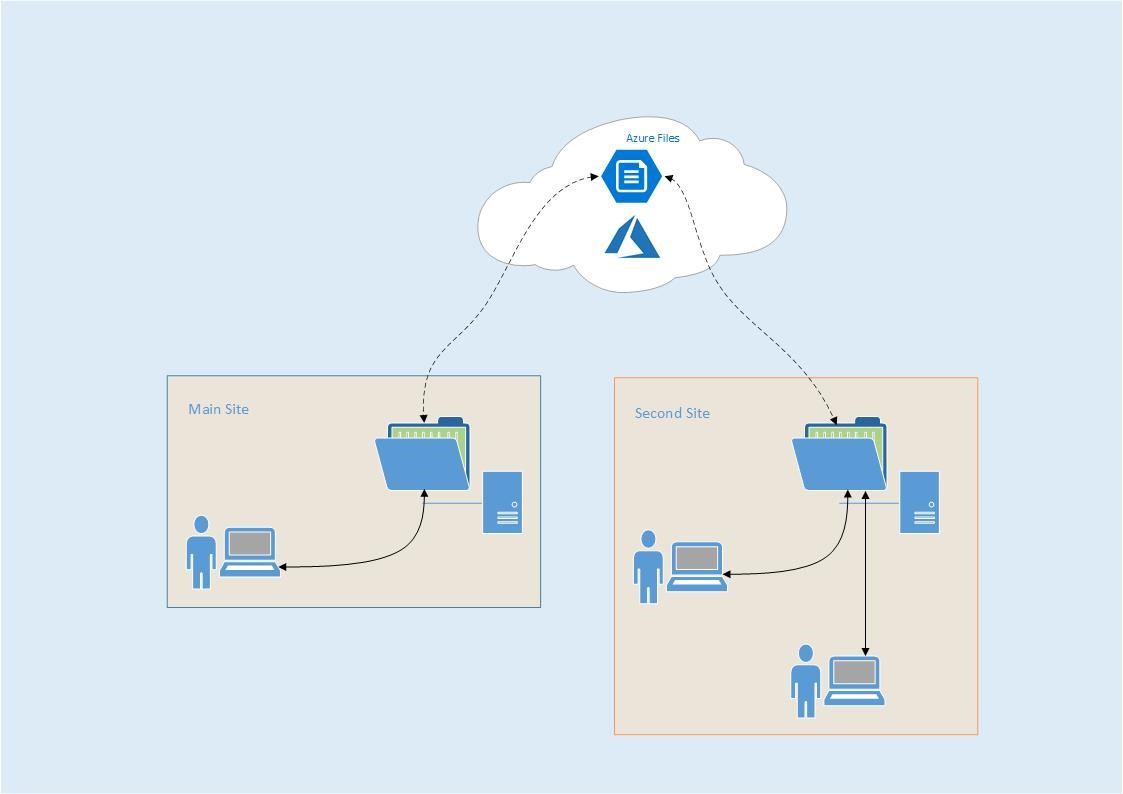
That could be useful for users who are distributed across multiple physical locations but need to work on the same data set, or for users who roam between locations. Yes, you could put their data in a cloud location, but as we’ve discussed before that won’t necessarily be the best solution for them.
Now is probably a good time to mention permissions again. As highlighted previously, Azure Files doesn’t currently support granular permissions, but the on-premise file share does. With Azure File Sync, those ACLs are synchronised to server endpoints, so security is maintained across the Sync Group.
Disaster Recovery of a Server Endpoint
So, what happens if disaster strikes and the sever on which the endpoint is hosted fails? Well, there are a couple of potential approaches. The preferred option would be to recover the server or build a new one, join it to the Sync Group and allow synchronisation of data back to the endpoint. From an Azure File Sync perspective, it doesn’t matter whether the server is the one that failed or a brand new one – so that fits with the modern view that the server is a commodity that should be easily replaceable. Of course, depending on how you approach it you may need to make some other configuration adjustments for everything to line up again – because the server name is in the share path, for example.
The second option is the good old recover the data from backup approach. That’s okay, but has to be approached with care – and it could be slower to reunite the users with their data. You wouldn’t be restoring the master as that’s the cloud endpoint, so things could be out of sync for a while – you have live data in Azure and could be restoring from a backup taken some time ago. Perhaps it’s better to just let the master data sync down from the cloud endpoint after all?
Future Developments
As mentioned before, Azure File Sync is still in preview, and is still developing. The signs are that it will develop to become a much richer solution, which will make it even more attractive. Below are some of the developments yet to come:
- Deployment to more regions. At the time of writing the regions available are Australia East, Southeast Asia, West Europe, West US, Canada Central, East US, and UK South.
- ACLs. We’re anticipating a solution enhancement that will enable support for Azure Active Directory (AAD) permissions on the Azure Files share – the cloud endpoint – which makes anywhere access much more feasible. Not only will data access be permission-controlled, but it will also remove the requirement for the user to have the Storage Account key to access that share.
- Backup. Microsoft Azure Backup functionality will be enhanced to provide protection for the cloud endpoint. Snapshots will be configurable on a schedule so that periodic copies of the Azure Files share can be taken. Azure Backup will be used to store backups in the Recovery Services Vault.
- Pinning. Similar solutions, such as StorSimple, have the facility to pin important data so that it is always stored locally, even if it is infrequently accessed and would otherwise be tiered to the cloud. It is expected that this capability will be introduced at a later date.
- Server Core support. Currently, the agent required to register the server endpoint is not supported on Server Core deployments of Windows Server.
Limitations
There are also some current limitations, which may be addressed in the future as the service develops. A few relevant restrictions are listed below, and more can be found here:
- Data deduplication and cloud tiering are not supported on the same volume
- The server endpoint can only be on an NTFS volume. ReFS, FAT, FAT32, etc. are not currently supported
- The server endpoint cannot be on a system volume, or at the root of a volume
- Items with a path longer than 2048 characters will not sync
- Compression will not be preserved if changes are synced to the file from another endpoint
- The Azure Files share storage limit is 5TB, although it’s pretty unlikely our environments will have a single share with 5TB of data in it! This limit will be expanded in the future
Costs
Sadly, you don’t get much for nothing in this world, and Azure File Sync is no exception. As with any pay-as-you-go service, the cost will vary from customer to customer, based on usage and churn on the server hosting the file share, the amount of data stored, the Azure region(s) the Azure Files share is stored in and the data redundancy option selected (e.g. locally redundant – in the same data centre, geographically redundant – locally redundant plus asynchronous copies stored in a second data centre).
There’s also a monthly charge for each registered server, although the first server in each Storage Sync Service is free.
These are the listed charges at the time of writing – assuming locally redundant storage is selected. Of course, any payment plan is subject to change and these could be different via CSP:
- Storage £0.045 per GB per month
- Data access – Put, Create Container (per 10,000 operations) £0.0112
- Data access – List (per 10,000 operations) £0.0112
- Data access – All other operations except Delete (per 10,000 operations) £0.0012
- Data egress (first 5GB per month) £Free
- Data egress (5GB to 10TB per month) £0.065 per GB per month
- Sync Server £3.728 per month (equiv. $5 per month)
More detail, or a more up to date view if you’re reading this some time after I wrote it, can be found here.
The thing to remember though is that if the reason for adoption is to manage on premise storage constraints through tiering utilisation, these costs are offset against not having to invest further in on premise storage.
Conclusion
With Azure File Sync still in public preview and with some of its current constraints it doesn’t yet fit the bill for production usage.
Once some of those constraints have been addressed, bringing together the headline capabilities in our typical (multi-site) environments, with remote access, might look like this:
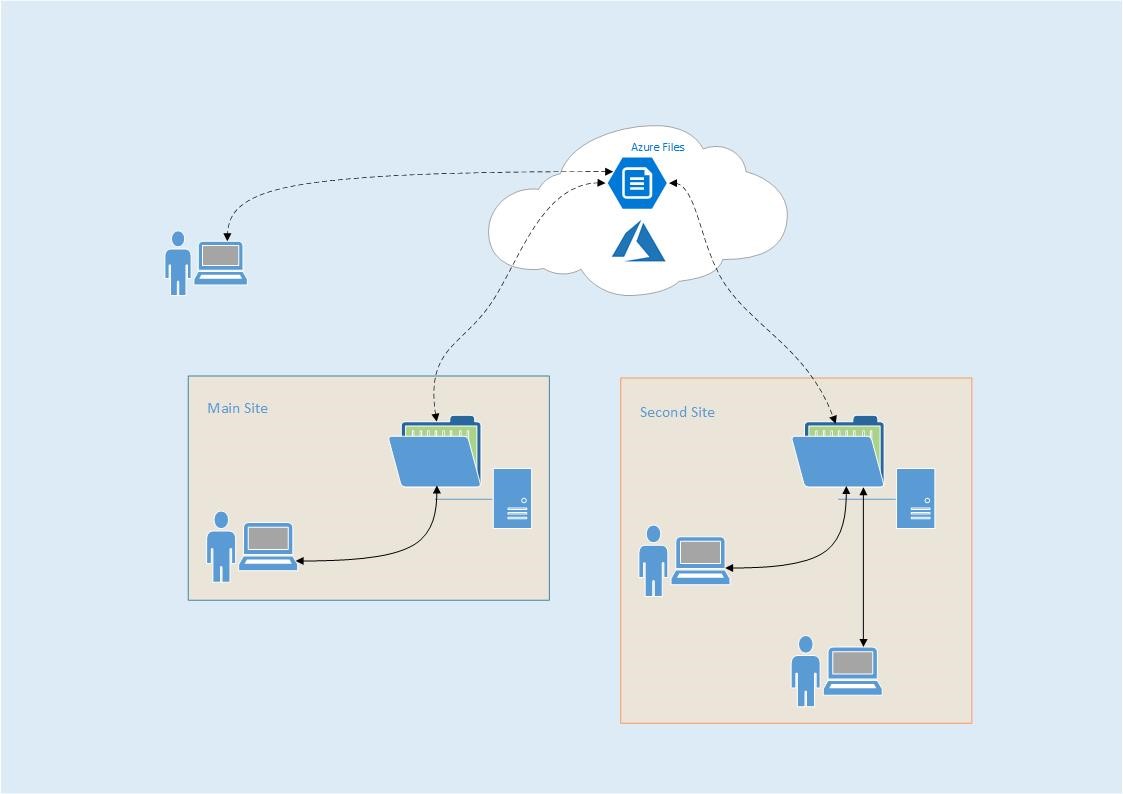
For some schools finding it hard to make progress in moving to the cloud - because of dependencies on legacy applications and drive mappings – Azure File Sync could be an inexpensive step in the right direction. It may help to initiate a shift in thinking that breaks the cycle of investing more in on premise infrastructure, instead supporting adoption of pay-as-you-go cloud services.
General availability is expected in Q2 2018.